线程池参数
- corePoolSize:核心线程数,线程池中始终存活的线程数。 根据业务类型设置
- CPU密集型:核心线程数 = CPU核数 + 1
- IO密集型:核心线程数 = CPU核数 × 2
- 混合型:通过压测找到最佳值
- maximumPoolSize: 最大线程数,线程池允许创建的最大线程数量,当线程池的任务队列满了之后,可以创建的最大线程数。
- keepAliveTime: 存活时间,线程没有任务执行时最多保持多久时间会终止。当线程池中没有任务时,会销毁一些线程,销毁的线程数 = maximumPoolSize(最大线程数) - corePoolSize(核心线程数)。
- unit: 单位,参数 keepAliveTime 的时间单位,7 种可选。空闲线程存活时间的描述单位,此参数是配合参数 3 使用的。 参数 3 是一个 long 类型的值,比如参数 3 传递的是 1,那么这个 1 表示的是 1 天?还是 1 小时?还是 1 秒钟?是由参数 4 说了算的。 TimeUnit 有以下 7 个值:
- TimeUnit.DAYS:天
- TimeUnit.HOURS:小时
- TimeUnit.MINUTES:分
- TimeUnit.SECONDS:秒
- TimeUnit.MILLISECONDS:毫秒
- TimeUnit.MICROSECONDS:微妙
- TimeUnit.NANOSECONDS:纳秒
- workQueue: 一个阻塞队列,用来存储等待执行的任务,均为线程安全,7 种可选。
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。 比较常用的是 LinkedBlockingQueue,线程池的排队策略和 BlockingQueue 息息相关。 // 1. 需要控制吞吐量 → LinkedBlockingQueue // 2. 需要快速响应 → SynchronousQueue(不缓存,直接传递) // 3. 需要优先级调度 → PriorityBlockingQueue // 4. 需要延迟执行 → DelayQueue
- threadFactory: 线程工厂,主要用来创建线程,默及正常优先级、非守护线程。
- handler:拒绝策略,拒绝处理任务时的策略,4 种可选。当线程池的任务超出线程池队列可以存储的最大值之后,执行的策略。 默认的拒绝策略有以下 4 种:
- AbortPolicy:拒绝并抛出异常。
- CallerRunsPolicy:使用当前调用的线程来执行此任务。
- DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
- DiscardPolicy:忽略并抛弃当前任务。 线程池的默认策略是 AbortPolicy 拒绝并抛出异常。
// 1. AbortPolicy(默认):直接抛出异常 // 适用:严格要求数据一致性的场景 new ThreadPoolExecutor.AbortPolicy();
// 2. CallerRunsPolicy:让调用线程执行任务
// 适用:需要保证每个任务都被执行的场景 new ThreadPoolExecutor.CallerRunsPolicy();
// 3. DiscardPolicy:静默丢弃任务 // 适用:日志记录、统计信息等可丢失的场景 new ThreadPoolExecutor.DiscardPolicy();
// 4. DiscardOldestPolicy:丢弃队列中最老的任务 // 适用:实时性要求高,老数据可丢弃的场景 new ThreadPoolExecutor.DiscardOldestPolicy();
线程池执行流程
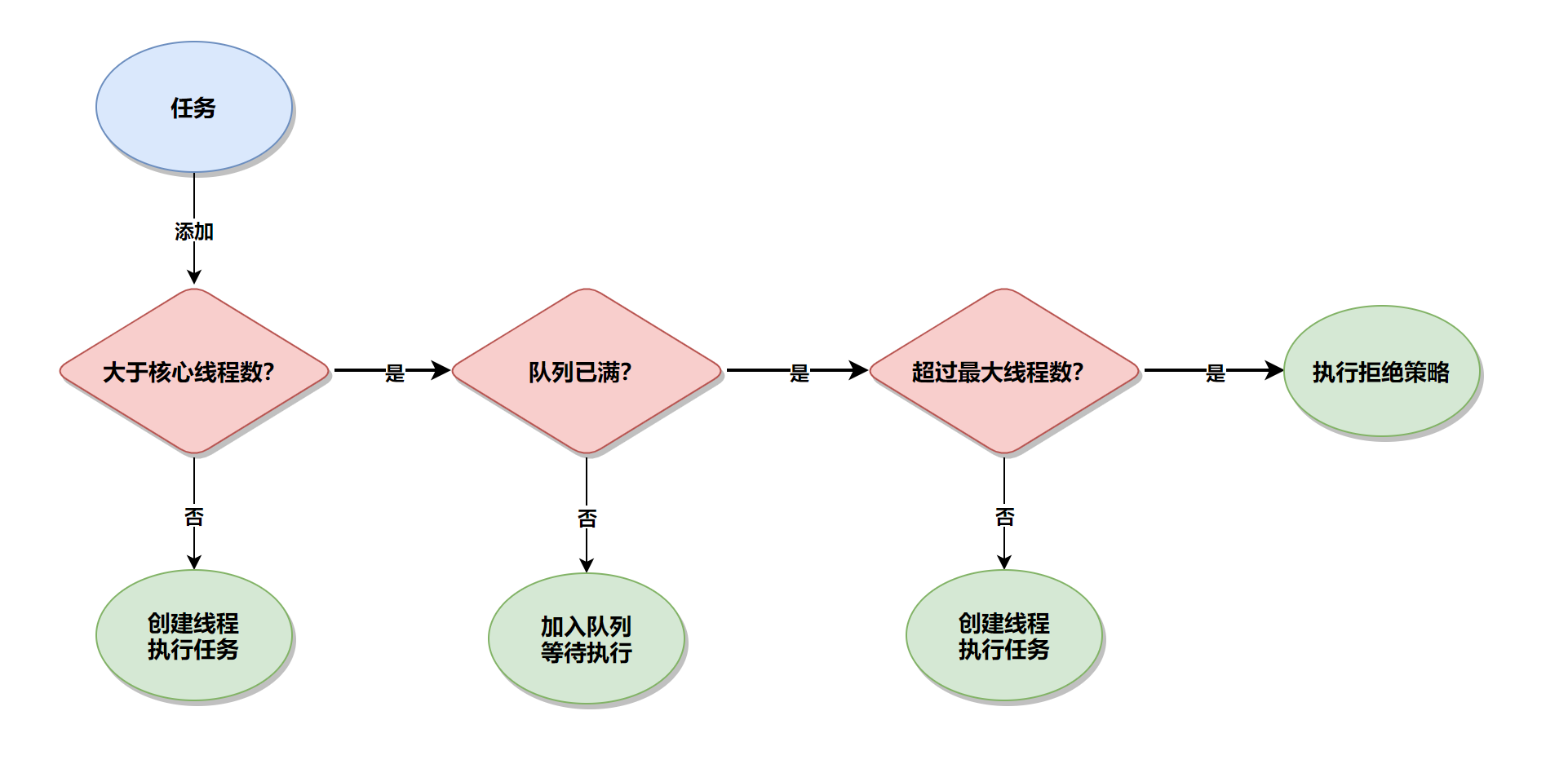
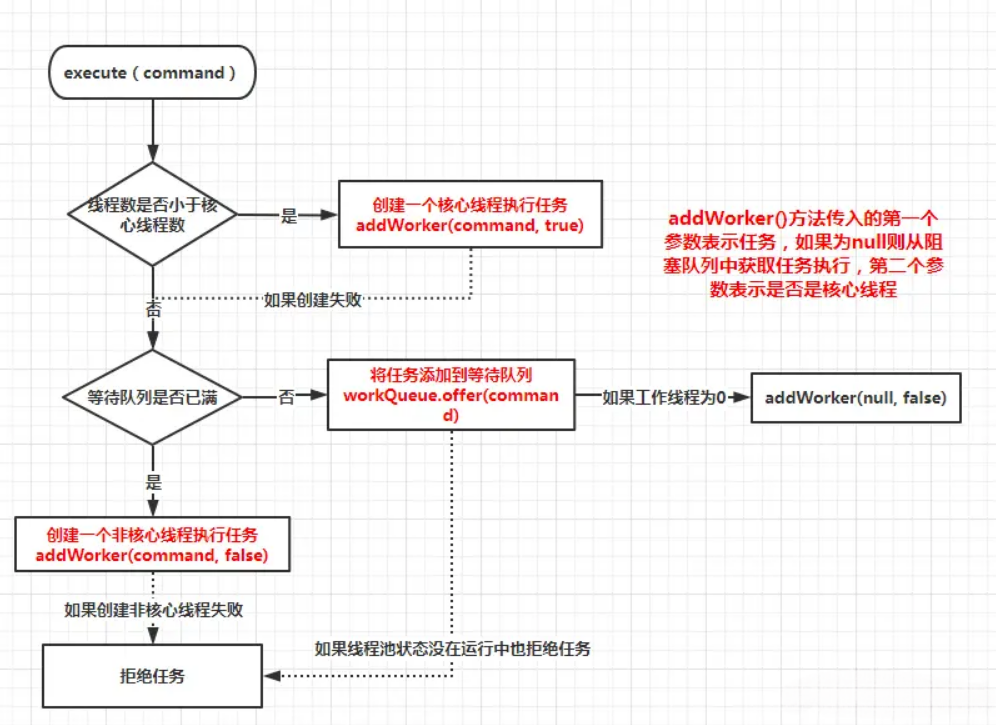 判断线程池中的线程数是否大于设置的核心线程数
判断线程池中的线程数是否大于设置的核心线程数
- 如果小于,就创建一个核心线程来执行任务
- 如果大于,就会判断缓冲队列是否满了
- 如果没有满,则放入队列,等待线程空闲时执行任务
- 如果队列已经满了,则判断是否达到了线程池设置的最大线程数
- 如果没有达到,就创建新线程来执行任务
- 如果已经达到了最大线程数,则执行指定的拒绝策略
核心线程不会销毁
线程池阻塞队列
- ArrayBlockingQueue 基于数组的有界阻塞队列,按FIFO排序,当线程数量达到线程池核心线程数(
corePoolSize)时,新的任务会放入队列的队尾,当队列满了时,会创建一个新的线程,当线程数达到线程池最大线程数(MaxnumPoolSize)时会执行拒绝策略。 - LinkedBlockingQueue 基于链表的无界阻塞队列(最大容量为
Integer.MAX),按FIFO排序,当线程数达到线程池核心线程数(corePoolSize)时,新的任务会进入队列等待而不会创建新的线程直到队列达到Integer.MAX - SynchronousQueue 不缓存任务的阻塞队列,直接执行任务,没有线程可以用时会新建线程,直到线程数达到线程池最大线程数(
MaxnumPoolSize)时,执行拒绝策略 - PriorityBlockingQueue 具有优先级的无界阻塞队列,优先级通过参数
Comparator实现
线程池拒绝策略
- AbortPolicy:直接丢弃任务,抛出异常,这是默认策略
- CallerRunsPolicy:只用调用者所在的线程来处理任务
- DiscardOldestPolicy:丢弃等待队列中最旧的任务,并执行当前任务
- DiscardPolicy:直接丢弃任务,也不抛出异常
当然除了 JDK 提供的四种拒绝策略之外,我们还可以实现通过 new RejectedExecutionHandler,并重写 rejectedExecution 方法来实现自定义拒绝策略,实现代码如下:
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 在这里处理拒绝的任务
System.err.println("任务被拒绝执行: " + r.toString());
// 可以选择记录日志、抛出自定义异常或采取其他措施
// 例如,可以将任务保存到某个队列中,稍后再尝试重新执行
}
}使用自定义策略
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolDemo {
public static void main(String[] args) {
// 配置线程池参数
int corePoolSize = 5;
int maximumPoolSize = 10;
long keepAliveTime = 60L;
TimeUnit unit = TimeUnit.SECONDS;
int queueCapacity = 25;
// 创建一个阻塞队列
ArrayBlockingQueue<Runnable> workQueue =
new ArrayBlockingQueue<>(queueCapacity);
// 创建 ThreadPoolExecutor 实例
try (ThreadPoolExecutor executor = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
new CustomRejectedExecutionHandler() // 使用自定义的拒绝策略 ,也可以直接用lambda表达式重写rejectedExecution方法
)) {
// 提交任务
for (int i = 0; i < 50; i++) {
final int taskId = i;
executor.execute(() -> {
System.out.println("执行任务: " + taskId + " 由线程 " + Thread.currentThread().getName() + " 执行");
try {
Thread.sleep(1000); // 模拟耗时任务
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 关闭线程池(这不会立即停止所有正在执行的任务)
executor.shutdown();
}
}
}
线程池优点
线程池相比于线程来说,它不需要频繁的创建和销毁线程,线程一旦创建之后,默认情况下就会一直保持在线程池中,等到有任务来了,再用这些已有的线程来执行任务,如下图所示: 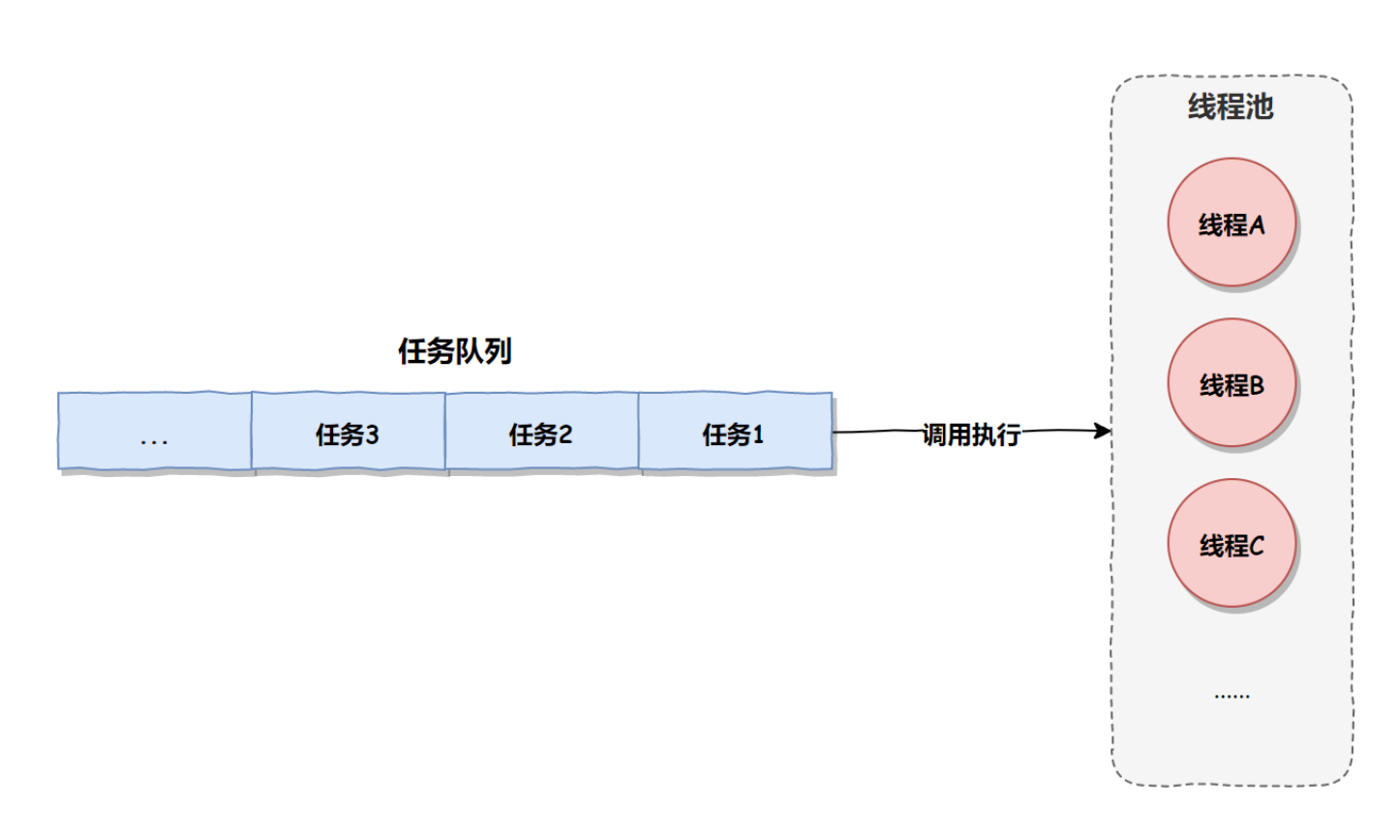
- 优点1:复用线程,降低资源消耗
线程在创建时要开辟虚拟机栈、本地方法栈、程序计数器等私有线程的内存空间,而销毁时又要回收这些私有空间资源,如下图所示: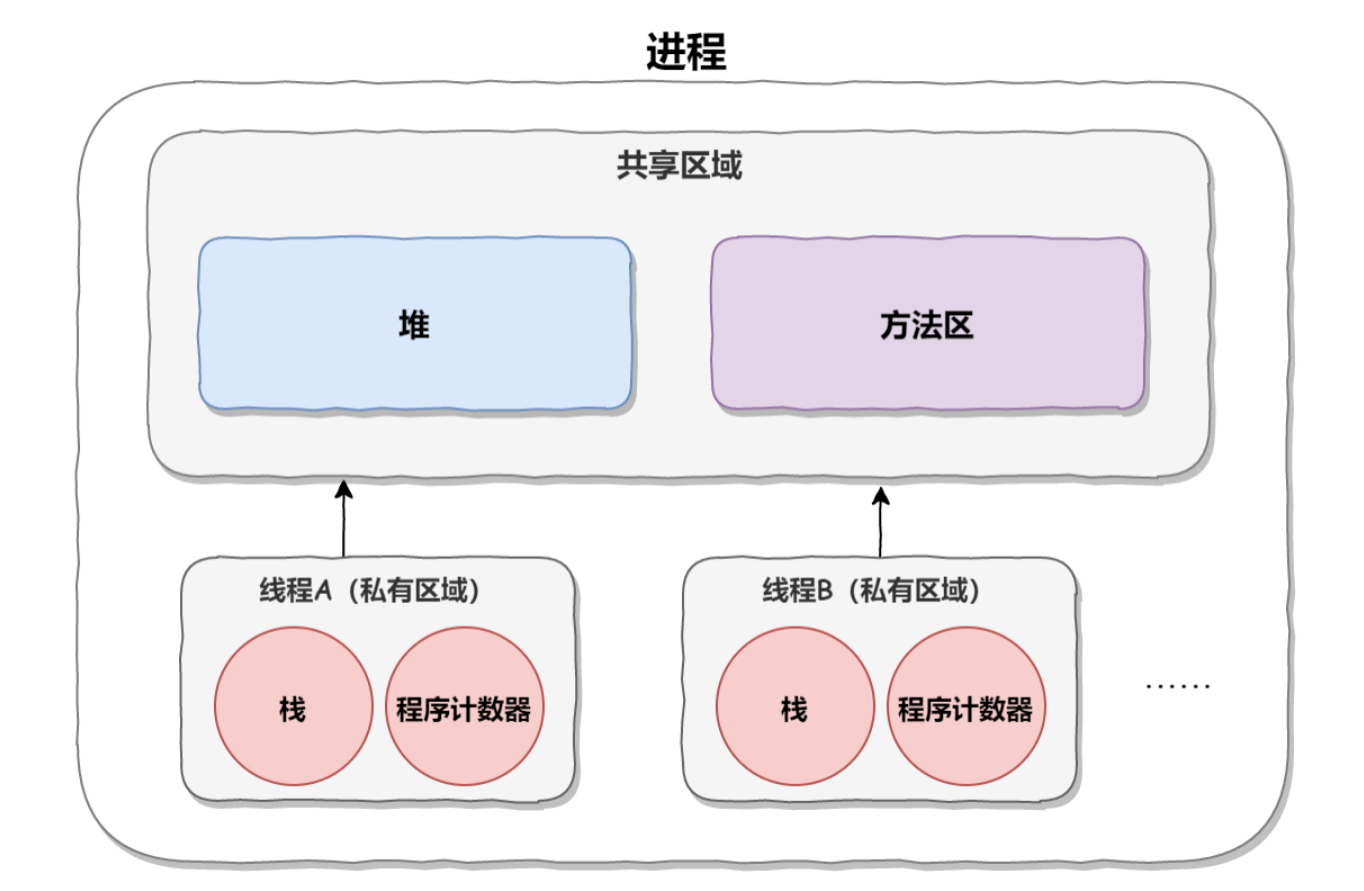 而线程池创建了线程之后就会放在线程池中,因此线程池相比于线程来说,第一个优点就是可以复用线程、减低系统资源的消耗。
而线程池创建了线程之后就会放在线程池中,因此线程池相比于线程来说,第一个优点就是可以复用线程、减低系统资源的消耗。 - 优点2:提高响应速度
线程池是复用已有线程来执行任务的,而线程是在有任务时才新建的,所以相比于线程来说,线程池能够更快的响应任务和执行任务。 - 优点3:管控线程数和任务数 线程池提供了更多的管理功能,这里管理功能主要体现在以下两个方面:
- 控制最大并发数:线程池可以创建固定的线程数,从而避免了无限创建线程的问题。当线程创建过多时,会导致系统执行变慢,因为 CPU 核数是一定的、能同时处理的任务数也是一定的,而线程过多时就会造成线程恶意争抢和线程频繁切换的问题,从而导致程序执行变慢,所以合适的线程数才是高性能运行的关键。
- 控制任务最大数:如果任务无限多,而内存又不足的情况下,就会导致程序执行报错,而线程池可以控制最大任务数,当任务超过一定数量之后,就会采用拒绝策略来处理多出的任务,从而保证了系统可以健康的运行。
- 优点4:更多增强功能 线程池相比于线程来说提供了更多的功能,比如定时执行和周期执行等功能。
小结
线程池是一种管理和复用线程资源的机制。相比于线程,它具备四个主要优势:
- 复用线程,降低了资源消耗;
- 提高响应速度;
- 提供了管理线程数和任务数的能力;
- 更多增强功能。
停止线程池
在 Java 中,停止线程池可以通过以下两个步骤来实现:
调用方法停止线程池:
- 调用线程池的
shutdown()方法来关闭线程池。该方法会停止线程池的接受新任务,并尝试将所有未完成的任务完成执行; - 调用线程池的
shutdownNow()方法来关闭线程池。该方法会停止线程池的接受新任务,并尝试停止所有正在执行的任务。该方法会返回一个未完成任务的列表,这些任务将被取消。
等待线程池停止:在关闭线程池后,通过调用awaitTermination()方法来等待所有任务完成执行。该方法会阻塞当前线程,直到所有任务完成执行或者等待超时。
下面是一个示例代码,演示如何中止线程池:
ExecutorService executor = Executors.newFixedThreadPool(10);
// 提交任务到线程池
for (int i = 0; i < 100; i++) {
executor.submit(new MyTask());
}
// 关闭线程池
executor.shutdown();
try {
// 等待所有任务完成执行
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
// 如果等待超时,强制关闭线程池
executor.shutdownNow();
}
} catch (InterruptedException e) {
// 处理异常
}在上面的示例代码中,首先创建了一个线程池,然后提交了 100 个任务到线程池中。然后,通过调用 shutdown() 方法关闭线程池,再通过调用 awaitTermination() 方法等待所有任务完成执行。如果等待超时,将强制调用 shutdownNow() 方法来停止所有正在执行的任务。最后,在 catch 块中处理中断异常。
下面,我将从核心线程数(corePoolSize)、最大线程数(maximumPoolSize)和队列长度(queueCapacity)三个关键参数的设计思路,以及它们之间的相互关系,为你提供一个系统性的解答。
理解ThreadPoolExecutor的工作原理
在深入探讨如何设置这些参数之前,我们必须先理解ThreadPoolExecutor是如何处理任务的。这对其参数设计至关重要。
当一个新任务提交时,线程池会按以下顺序处理:
- 核心线程:如果当前运行的线程数小于
corePoolSize,线程池会创建一个新的核心线程来处理任务,即使其他核心线程是空闲的。 - 任务队列:如果当前运行的线程数等于
corePoolSize,新任务会被放入工作队列中等待。 - 最大线程:如果队列已满,并且当前运行的线程数小于
maximumPoolSize,线程池会创建新的非核心线程来处理任务。 - 拒绝策略:如果队列已满,并且当前运行的线程数已经达到
maximumPoolSize,线程池将根据设定的拒绝策略(RejectedExecutionHandler)来处理这个任务。
这个流程揭示了这三个参数之间紧密的联动关系。
如何设计核心线程数(corePoolSize)
corePoolSize是线程池的基本大小,是即使在没有任务时也保持存活的线程数(除非设置了allowCoreThreadTimeOut)。它的设定主要取决于任务的类型。
1. 任务类型划分
- CPU密集型任务(CPU-bound):这类任务需要大量的CPU计算,例如复杂的算法、数据加密、图像处理等。线程基本不会因为等待外部资源(如I/O)而阻塞,CPU会一直处于高利用率状态。
- I/O密集型任务(I/O-bound):这类任务的大部分时间都在等待I/O操作完成,例如数据库查询、网络请求、文件读写等。在等待期间,CPU是空闲的,可以切换去执行其他任务。
2. 设置策略
对于CPU密集型任务:
- 理论值:
corePoolSize=CPU核心数+ 1 - 原因:设置过多的线程并没有好处,因为CPU核心在任何时候只能同时处理一个线程。过多的线程会导致频繁的上下文切换,反而降低性能。增加一个线程是为了防止某个线程因偶尔的页错误或其他原因而暂停时,CPU能够得到充分利用。
- 获取CPU核心数:
int cores = Runtime.getRuntime().availableProcessors();
- 理论值:
对于I/O密集型任务:
- 理论公式:
corePoolSize=CPU核心数* (1 +线程等待时间/线程CPU计算时间) 这个公式也等同于:corePoolSize=CPU核心数/ (1 -阻塞系数),其中阻塞系数是等待时间 / (等待时间 + CPU计算时间)。 - 原因:由于线程大部分时间在等待I/O,CPU处于空闲状态。因此,可以配置更多的线程,以便在一个线程等待时,其他线程可以使用CPU,从而提高CPU的利用率和整体吞吐量。
- 阻塞系数的估算:这是一个难点,精确计算很困难。在实践中,我们通常通过压测和监控来估算。可以使用性能分析工具(如VisualVM, JFR, Async-profiler)来观察线程的状态,估算等待时间与计算时间的比例。 如果没有精确的工具,可以从一个经验值开始,例如
2 * CPU核心数,然后通过压测进行调整。
- 理论公式:
如何设计最大线程数(maximumPoolSize)
maximumPoolSize定义了线程池能够创建的线程数上限。它为系统提供了应对突发流量的能力。
设置策略
maximumPoolSize必须大于或等于corePoolSize。- 它的大小通常与系统的资源限制有关,例如内存、数据库连接池大小、外部服务的并发限制等。
- 对于需要快速响应且任务处理时间短的场景:可以设置一个相对较大的
maximumPoolSize,以便在流量洪峰时能够快速创建新线程来处理任务,减少任务在队列中的等待时间。 - 对于资源有限的系统:需要谨慎设置
maximumPoolSize,以防止创建过多线程耗尽系统内存(每个线程大约需要1MB的栈空间)或导致过于激烈的资源竞争(如数据库连接)。 - 无界队列的特殊情况:如果使用
LinkedBlockingQueue这样的无界队列,maximumPoolSize实际上是不起作用的,因为队列永远不会满,线程池永远不会创建超过corePoolSize的线程。 这可能导致内存溢出,因此通常不推荐。
如何考虑队列长度(queueCapacity)
任务队列是核心线程与最大线程之间的缓冲地带。它的设计直接影响了线程池的资源利用率和任务处理行为。
1. 队列类型的选择
ArrayBlockingQueue:一个有界的阻塞队列,基于数组实现,遵循FIFO(先进先出)原则。它在性能上通常表现良好,并且可以防止资源耗尽。LinkedBlockingQueue:一个基于链表实现的可选有界/无界阻塞队列。如果不指定容量,默认为Integer.MAX_VALUE,相当于无界队列。吞吐量通常高于ArrayBlockingQueue。SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作都必须等待一个移除操作,反之亦然。它非常适合于需要“任务直达线程”的场景,通常需要将maximumPoolSize设置得非常大(甚至是Integer.MAX_VALUE),Executors.newCachedThreadPool()就使用了它。
2. 队列长度的设置
- 有界队列是推荐选择:使用有界队列(如
ArrayBlockingQueue或指定容量的LinkedBlockingQueue)是防止内存溢出的关键。 - 长度的权衡:
- 较短的队列:可以使线程池更快地达到
maximumPoolSize,从而创建新线程来处理任务。这有助于提高响应速度,但可能导致线程创建开销较大和资源消耗更多。 - 较长的队列:可以更好地缓冲突发任务,减少线程创建的频率。但这可能导致任务处理的延迟增加,并且在系统过载时消耗更多内存。
- 较短的队列:可以使线程池更快地达到
- 队列长度与最大线程数的关系:一个常见的做法是,根据系统的处理能力和可接受的延迟来设定队列长度。可以通过**利特尔法则(Little's Law)**来辅助思考:
队列长度≈任务到达速率*任务平均等待时间。 - 作为反压机制:一个有界队列实际上是一种反压(Backpressure)机制。当队列满了之后,如果线程数也达到最大,就会触发拒绝策略,这可以防止系统被无法处理的请求压垮。
综合实战场景举例
假设我们有一个8核CPU的服务器。
场景一:CPU密集型的批量计算任务
corePoolSize: 8 或 9maximumPoolSize: 8 或 9 (与核心线程数保持一致,因为增加更多线程无益)queueCapacity: 设置一个合理的有界值,如100。这个队列主要是为了缓冲任务提交的瞬间波动。- 拒绝策略:
CallerRunsPolicy,让提交任务的线程自己去执行,从而减缓任务提交的速度,形成一种自然的反馈。
场景二:高并发的Web应用,处理大量I/O密集型请求(如数据库查询、调用外部API)
- 假设通过压测估算,线程的等待时间大约是CPU计算时间的3倍(阻塞系数 = 3 / (3+1) = 0.75)。
corePoolSize: 8 * (1 + 3/1) = 32。可以从这个理论值开始测试。maximumPoolSize: 可以设置得更大一些,比如64,以应对突发流量。但要确保下游资源(如数据库连接池)能承受。queueCapacity: 设置一个有界值,比如500。如果队列满了并且达到了最大线程数,说明系统已经超载。- 拒绝策略:
AbortPolicy,直接抛出异常,让客户端或上游服务知道当前服务不可用,并触发相应的熔断或降级策略。
场景三:Kafka消费者
- Kafka消费者线程池的设计通常与分区数(Partitions)相关。为了保证顺序消费,一个分区通常只由一个线程处理。
- 因此,线程数通常设置为等于或小于分区数。如果一个消费者订阅了多个分区,可以将线程数设置为分区数。
corePoolSize和maximumPoolSize通常设置为相等,等于你希望并发处理的分区数量。
监控与调优:持续的艺术
理论计算和初始配置只是第一步。在生产环境中,监控是必不可少的。你需要关注以下指标:
poolSize:线程池中的当前线程数。activeCount:正在执行任务的线程数。queueSize:队列中等待的任务数。taskCount:已完成的任务总数。- Rejected Tasks:被拒绝的任务数。
通过Prometheus、Grafana等工具监控这些指标,你可以了解线程池的真实负载情况,并根据实际表现进行调优。 例如,如果activeCount经常达到maximumPoolSize,并且队列持续处于高位,这可能意味着你需要增加maximumPoolSize或优化任务处理逻辑。如果队列长期为空,而poolSize维持在corePoolSize,可能说明corePoolSize设置得过高,可以适当调低以节省资源。